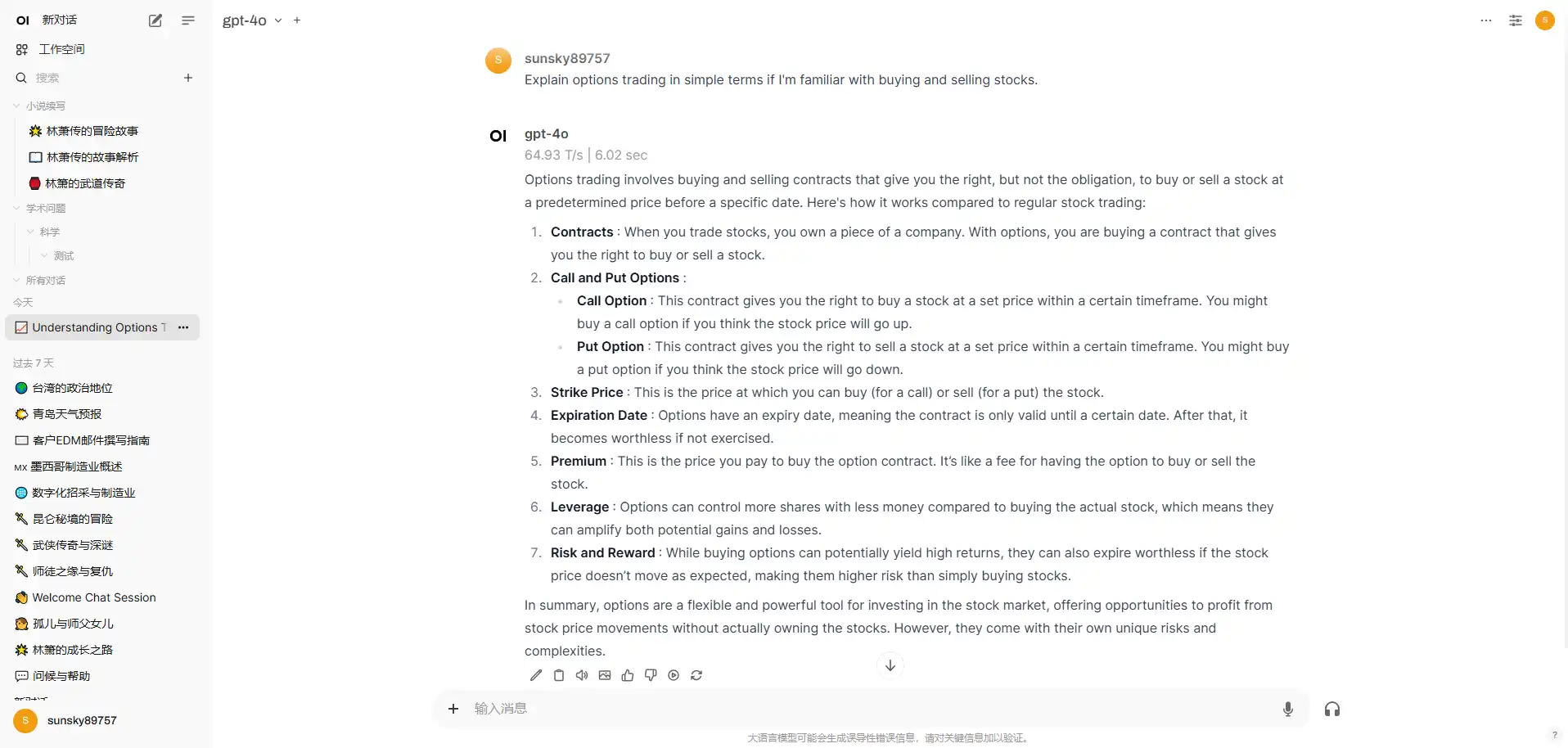
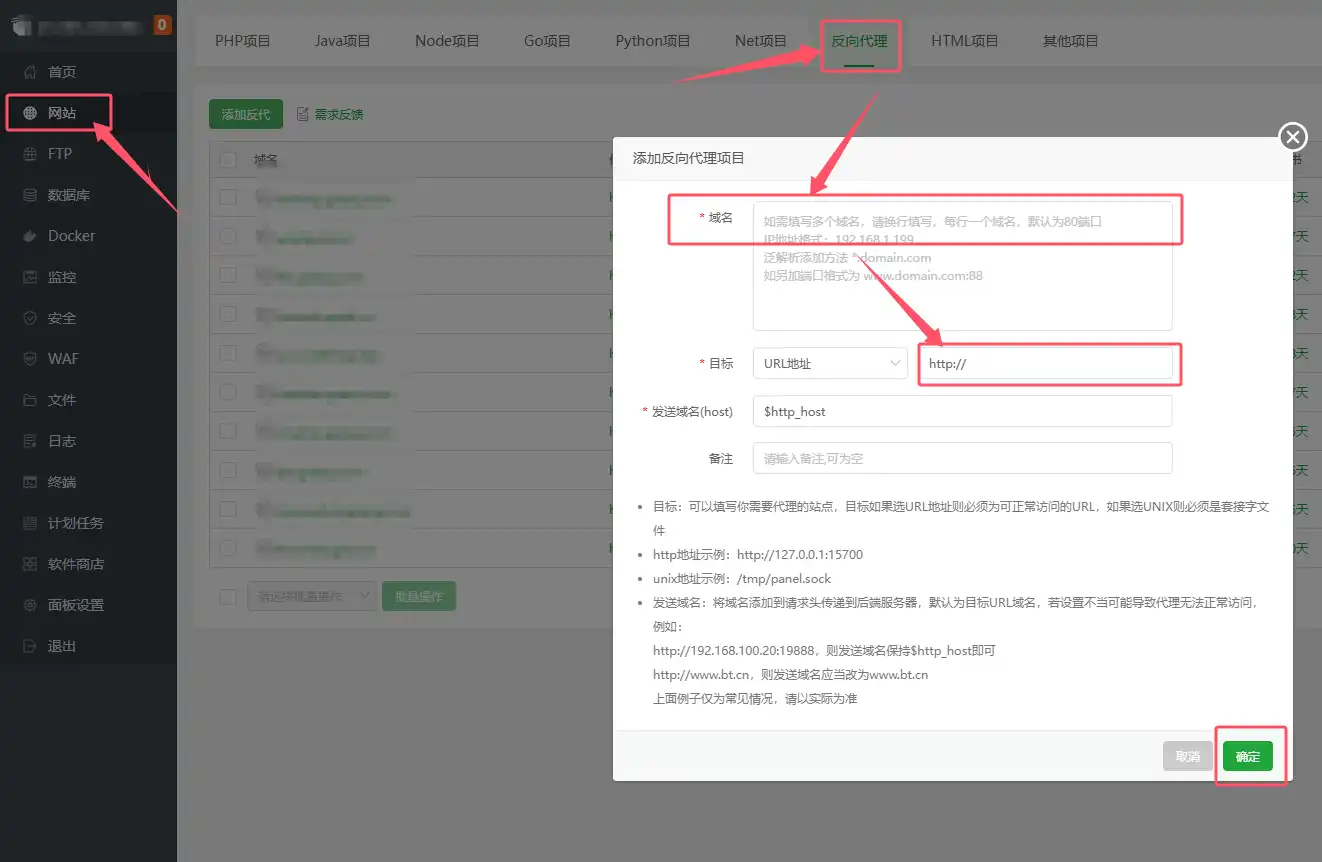
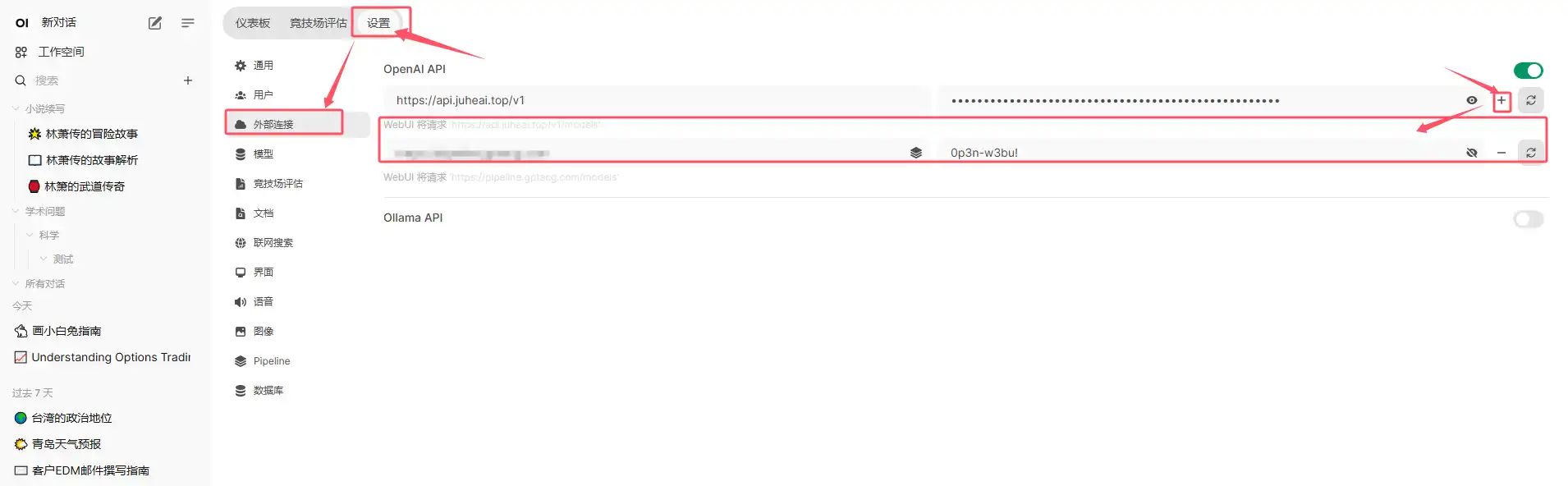
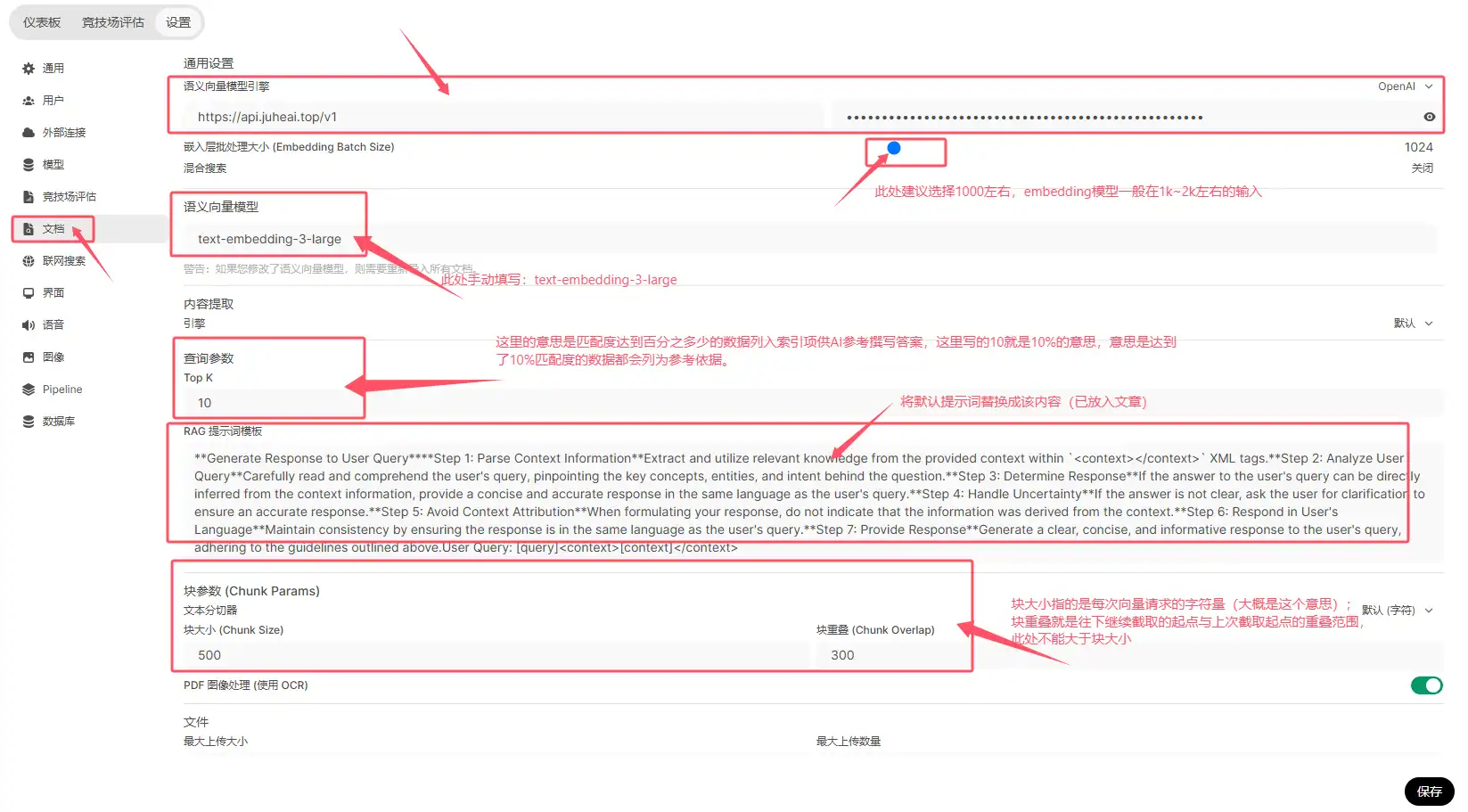
提示词:
**Generate Response to User Query****Step 1: Parse Context Information**Extract and utilize relevant knowledge from the provided context within `<context></context>` XML tags.**Step 2: Analyze User Query**Carefully read and comprehend the user's query, pinpointing the key concepts, entities, and intent behind the question.**Step 3: Determine Response**If the answer to the user's query can be directly inferred from the context information, provide a concise and accurate response in the same language as the user's query.**Step 4: Handle Uncertainty**If the answer is not clear, ask the user for clarification to ensure an accurate response.**Step 5: Avoid Context Attribution**When formulating your response, do not indicate that the information was derived from the context.**Step 6: Respond in User's Language**Maintain consistency by ensuring the response is in the same language as the user's query.**Step 7: Provide Response**Generate a clear, concise, and informative response to the user's query, adhering to the guidelines outlined above.User Query: [query]<context>[context]</context>